
ダンス動画をVertex AIでベクトル化してQdrantで類似検索してみた

リテールアプリ共創部@大阪の岩田です。
動画のベクトル検索を試してみたいと思って適当なデータセットを探していたところ、AIST Dance Video Databaseという面白そうなサイトを見つけました。このブログでは上記サイトで公開されているデータセットとVertex AI、Qdrantを組み合わせてダンス動画のベクトル検索を試していきます。
環境
今回利用した環境は以下の通りです。
- Python: 3.12.3
- google-cloud-aiplatform: 1.68.0
- qdrant-client: 1.11.3
- Qdrant: v1.11.3
AIST Dance Video Databaseとは
AIST Dance Video Databaseはストリートダンス動画のデータベースで、様々なジャンルやシチュエーション、撮影方向を網羅したデータベースとなっているのが特徴です。
このデータベースの詳細については以下の論文に記載されています。
Shuhei Tsuchida, Satoru Fukayama, Masahiro Hamasaki and Masataka Goto. AIST Dance Video Database: Multi-genre, Multi-dancer, and Multi-camera Database for Dance Information Processing. In Proceedings of the 20th International Society for Music Information Retrieval Conference (ISMIR 2019), 2019.
また公式サイトの利用規約には以下のように記載されており、研究目的であれば無償でデータベースが利用可能となっています。
AIST Dance DB may not be used for any purpose other than academic research. It is free to use for research purposes by academic institutes, companies, and individuals. Use for commercial purposes is not permitted without prior written consent from AIST.
本ブログの執筆にあたっても以下の申請フォームに必要事項を記入して提出させて頂きました。
データベースの準備
ここからAIST Dance Video Databaseの動画を利用した類似検索に挑戦します。まずは前準備として動画をベクトル化してQdrantに登録していきます。
ダンス動画をVertex AIでベクトル化する
まず動画のベクトル化です。全部の動画をベクトル化すると時間・コスト共に大きくなってしまうので、今回はCompact subset (an example of refined videos)をVertex AIでベクトル化することにしました。Generative AI on Vertex AIの公式ドキュメントで紹介されているサンプルコードを流用してベクトル化した結果をJSONLファイルに出力しています。JSONLファイルに出力しているのはトライ&エラーのたびにVertex AIのAPIを呼び出さなくて済むようにするのが目的です。
以下のコードは公式ドキュメントのサンプルにreturn embeddingsを追加して動画のエンベディングを取得する関数を定義したものです。
from typing import Optional
import vertexai
from vertexai.vision_models import (
MultiModalEmbeddingModel,
MultiModalEmbeddingResponse,
Video,
VideoSegmentConfig,
)
def get_video_embeddings(
project_id: str,
location: str,
video_path: str,
contextual_text: Optional[str] = None,
dimension: Optional[int] = 1408,
video_segment_config: Optional[VideoSegmentConfig] = None,
) -> MultiModalEmbeddingResponse:
"""Example of how to generate multimodal embeddings from video and text.
Args:
project_id: Google Cloud Project ID, used to initialize vertexai
location: Google Cloud Region, used to initialize vertexai
video_path: Path to video (local or Google Cloud Storage) to generate embeddings for.
contextual_text: Text to generate embeddings for.
dimension: Dimension for the returned embeddings.
https://cloud.google.com/vertex-ai/docs/generative-ai/embeddings/get-multimodal-embeddings#low-dimension
video_segment_config: Define specific segments to generate embeddings for.
https://cloud.google.com/vertex-ai/docs/generative-ai/embeddings/get-multimodal-embeddings#video-best-practices
"""
vertexai.init(project=project_id, location=location)
model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
video = Video.load_from_file(video_path)
embeddings = model.get_embeddings(
video=video,
video_segment_config=video_segment_config,
contextual_text=contextual_text,
dimension=dimension,
)
# Video Embeddings are segmented based on the video_segment_config.
print("Video Embeddings:")
for video_embedding in embeddings.video_embeddings:
print(
f"Video Segment: {video_embedding.start_offset_sec} - {video_embedding.end_offset_sec}"
)
print(f"Embedding: {video_embedding.embedding}")
print(f"Text Embedding: {embeddings.text_embedding}")
return embeddings
この関数を呼び出してデータセット内の動画を全てベクトル化します。
import json
import os
from lib import get_video_embeddings
base_path = '<データセットをダウンロードしたフォルダ>'
mp4_files = [f for f in os.listdir(base_path) if f.endswith('.mp4')]
with open("<JSONLファイルの出力先パス>", "w") as f:
for mp4_file in mp4_files:
res = get_video_embeddings(project_id='<Google CloudのプロジェクトID>',location='us-west1',video_path=f"{base_path}{mp4_file}")
i = 0
for video_embedding in res.video_embeddings:
i += 1
data = {
"file_name": mp4_file,
"seq": i,
"start_offset_sec": video_embedding.start_offset_sec,
"end_offset_sec": video_embedding.end_offset_sec,
"embedding": video_embedding.embedding
}
json_line = json.dumps(data)
f.write(json_line + "\n")
エンベディングをQdrantに登録する
データの準備ができたのでDockerでQdrantを起動します。
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
--name qdrant \
qdrant/qdrant
続いて以下のコードでエンベディングをQdrantに登録します。
import json
from qdrant_client import QdrantClient, models
embeddings = []
with open('先ほど作成したJSONLファイル') as f:
for line in f:
embeddings.append(json.loads(line))
solo_movies = filter(lambda x: x['file_name'].split('_')[1] not in ['sGR','sSH','sCY','sBT'],embeddings)
qdrant_client = QdrantClient(url="http://localhost:6333")
qdrant_client.create_collection(
"dance_movies",
vectors_config=models.VectorParams(size=1408, distance=models.Distance.COSINE),
)
i = 0
genre_dict = {
'gBR': 'Break',
'gPO': 'Pop',
'gLO': 'Lock',
'gMH': 'Middle Hip-hop',
'gLH': 'LA style Hip-hop',
'gHO': 'House',
'gWA': 'Waack',
'gKR': 'Krump',
'gJS': 'Street Jazz',
'gJB': 'Ballet Jazz'
}
situation_dict = {
'sBM': 'Basic Dance',
'sFM': 'Advanced Dance',
'sMM': 'Moving Camera',
'sGR': 'Group Dance',
'sSH': 'Showcase',
'sCY': 'Cypher',
'sBT': 'Battle',
}
for movie in solo_movies:
i += 1
file_name = movie['file_name']
movie_info = file_name.split('_')
genre = movie_info[0]
situation = movie_info[1]
camera_id = movie_info[2]
dancer_id = movie_info[3]
payload = {
'file_name': movie['file_name'],
'seq': movie['seq'],
'start_offset_sec': movie['start_offset_sec'],
'end_offset_sec': movie['end_offset_sec'],
'genre': genre_dict[genre],
'situation': situation_dict[situation],
}
qdrant_client.upsert(
"dance_movies",
points=[models.PointStruct(id=i, vector=movie['embedding'],payload=payload)],
)
solo_movies = filter(lambda x: x['file_name'].split('_')[1] not in ['sGR','sSH','sCY','sBT'],embeddings)この処理ですが、データセットに含まれる動画から複数名が写っている動画は登録対象外になるようにフィルタしています。(最初からベクトル化の対象外にしてれば良かった...)
データセットのファイル名はNaming Rulesの通り命名されており、_でsplitした2要素目が動画のシチュエーションになります。今回は複数名が登場する以下のシチュエーションを除外しています。
- sGR... グループダンス
- sSH... ショーケース
- sCY... サイファー
- sBT... バトル
Pointに設定するペイロードは以下のように生成しています。
payload = {
'file_name': movie['file_name'],
'seq': movie['seq'],
'start_offset_sec': movie['start_offset_sec'],
'end_offset_sec': movie['end_offset_sec'],
'genre': genre_dict[genre],
'situation': situation_dict[situation],
}
それぞれの意味は以下の通りです。
- file_name... 元データのファイル名
- seq... 同一ファイル中のシーケンス 1つの動画が複数のエンベディングに分割されることもあるため、ベクトル化の段階で連番を採番しています。今回の実装であれば動画の再生時間16秒毎に1つのエンベディングが出力されます。
- start_offset_sec... 対象のエンベディングが元データの何秒〜何秒に存在するかを表すオフセット値(開始)
- end_offset_sec... 対象のエンベディングが元データの何秒〜何秒に存在するかを表すオフセット値(終了)
- genre... ダンスのジャンル 元データのファイル名を
_でsplitして付与 - situation... ダンス動画のシチュエーション 元データのファイル名を
_でsplitして付与
可視化してみる
エンベディングをQdrantに登録できたらダッシュボードから可視化してみましょう。
http://localhost:6333/dashboard#/collections/dance_movies/visualizeから以下のペイロードを送信して、ダンスのジャンルごとにどのように分布しているか可視化してみます。
{
"limit": 500,
"color_by": "genre"
}
結果は以下のようになりました。

Waackなどは割と集中して分布しているのに対してPopなどは比較的まばらに分布していることが分かります。
類似検索してみる
データセットの準備ができたので、ここからはダンス動画を使って類似検索を行います。以降はPythonのインタプリタから作業していきます。
検索の手順は以下の通りです。
- 先ほどと同じ要領で検索に利用する動画をVertex AIでベクトル化してJSONLファイルに出力します。
※詳細な手順は割愛します。
- その後JSONLファイルからエンベディングを読み込みます。
import json
embeddings = []
with open('JSONLファイルのパス') as f:
for line in f:
embeddings.append(json.loads(line))
- 続いて読み込んだエンベディングを使ってQdrantにクエリを投げます。
from qdrant_client import QdrantClient
qdrant_client = QdrantClient(url="http://localhost:6333")
vector = embeddings[0]["embedding"]
query_res = qdrant_client.query_points(
"dance_movies",
query=vector,
limit=3
)
- 最後に結果を出力します。
from pprint import pprint
pprint([p.dict() for p in query_res.points])
フットワークの動画に類似する動画の検索
さっそくダンス動画の類似検索をやっていきたいところなのですが、筆者は前十字靭損傷のリハビリ中で動けないため、後輩から提供してもらった動画を使って検索してみます。検索に使った動画はブレイクダンスのフットワークの動画で一部を切り出すとこんな感じです。

検索結果は以下の通りとなりました。上位3件ともgenreがBreakなのでいい感じではないでしょうか?
[{'id': 113,
'order_value': None,
'payload': {'end_offset_sec': 34.0,
'file_name': 'gBR_sMM_c10_d06_mBR3_ch08.mp4',
'genre': 'Break',
'seq': 2,
'situation': 'Moving Camera',
'start_offset_sec': 32.0},
'score': 0.7431293,
'shard_key': None,
'vector': None,
'version': 112},
{'id': 112,
'order_value': None,
'payload': {'end_offset_sec': 32.0,
'file_name': 'gBR_sMM_c10_d06_mBR3_ch08.mp4',
'genre': 'Break',
'seq': 1,
'situation': 'Moving Camera',
'start_offset_sec': 16.0},
'score': 0.74198574,
'shard_key': None,
'vector': None,
'version': 111},
{'id': 105,
'order_value': None,
'payload': {'end_offset_sec': 32.0,
'file_name': 'gBR_sMM_c10_d04_mBR3_ch01.mp4',
'genre': 'Break',
'seq': 1,
'situation': 'Moving Camera',
'start_offset_sec': 16.0},
'score': 0.73797756,
'shard_key': None,
'vector': None,
'version': 104}]
1番類似度が高かった動画は gBR_sMM_c10_d06_mBR3_ch08.mp4の32~34秒、2番目は同じ動画の16~32秒という結果でした。動画の一部を画像に切り出すとこんな感じです。

検索に使った動画と割と似たような動きではないでしょうか?
世界一横であろう1990に類似する動画の検索
続いてリルオッサ氏による「世界一横であろう1990」に類似する動画を検索してみます。
ちなみに「世界一横であろう1990」はこちらです。ダンスのジャンルはブレイクダンスになります。
さらに補足すると今回Qdrantに登録しているCompact subsetの動画の中には1990という技を行っている動画は存在しません。果たしてこの条件下でどんな検索結果が出るのでしょうか?
検索結果は以下の通りとなりました。
[{'id': 184,
'order_value': None,
'payload': {'end_offset_sec': 32.0,
'file_name': 'gLH_sFM_c01_d17_mLH3_ch11.mp4',
'genre': 'LA style Hip-hop',
'seq': 1,
'situation': 'Advanced Dance',
'start_offset_sec': 16.0},
'score': 0.72696483,
'shard_key': None,
'vector': None,
'version': 183},
{'id': 199,
'order_value': None,
'payload': {'end_offset_sec': 16.0,
'file_name': 'gPO_sFM_c01_d12_mPO3_ch18.mp4',
'genre': 'Pop',
'seq': 3,
'situation': 'Advanced Dance',
'start_offset_sec': 0.0},
'score': 0.72446185,
'shard_key': None,
'vector': None,
'version': 198},
{'id': 45,
'order_value': None,
'payload': {'end_offset_sec': 34.0,
'file_name': 'gPO_sMM_c10_d12_mPO3_ch08.mp4',
'genre': 'Pop',
'seq': 3,
'situation': 'Moving Camera',
'start_offset_sec': 32.0},
'score': 0.7239723,
'shard_key': None,
'vector': None,
'version': 44}]
データベース内に1990の動画が含まれていないことが影響してか、検索結果の上位3件は別ジャンルの動画が抽出されました。1位になったgLH_sFM_c01_d17_mLH3_ch11.mp4 の16~32秒はこんな感じです。
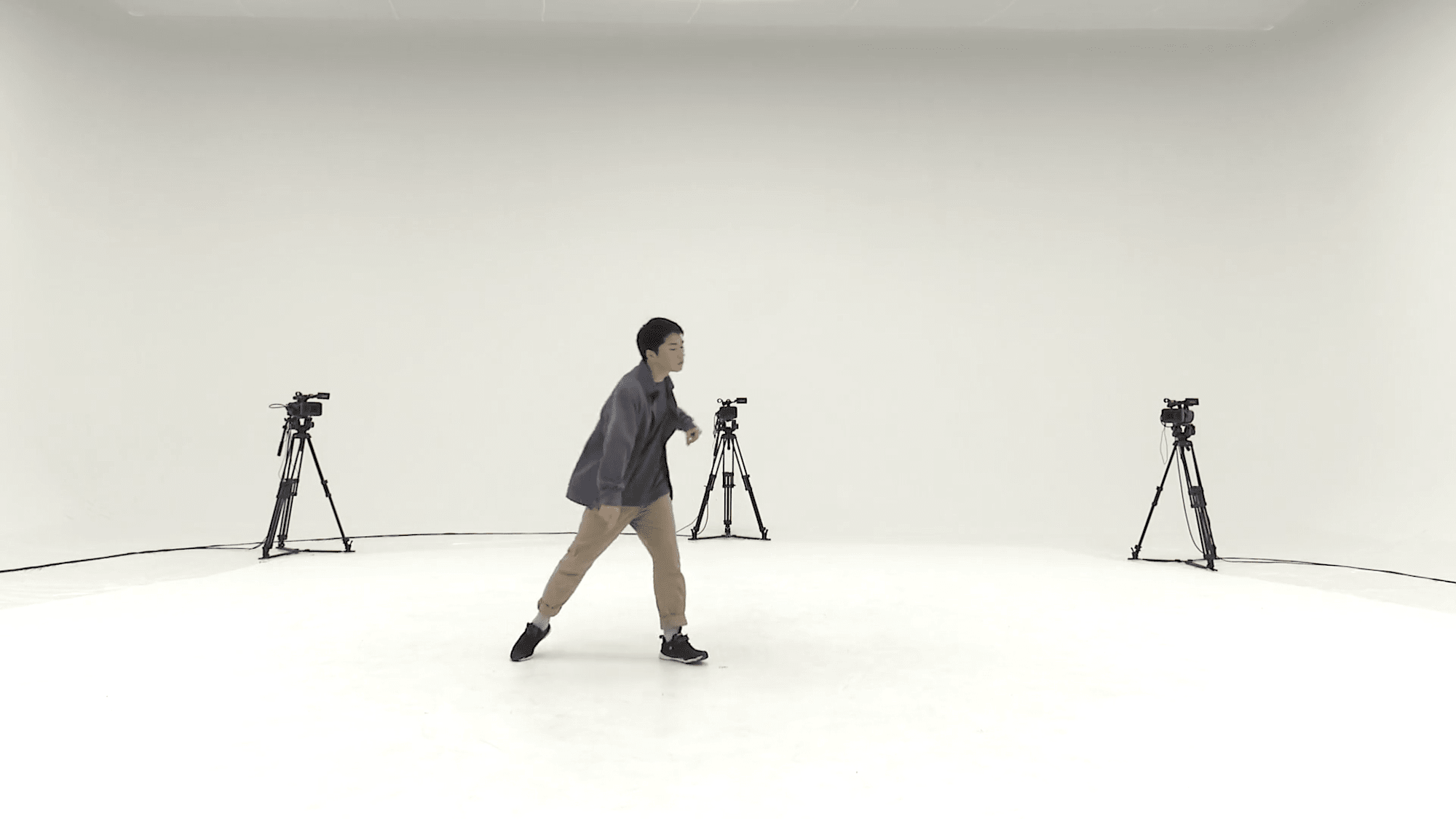
ブレイクダンスに限定してコレクションを作り直す
リルオッサ氏の1990に類似した動画がうまく見つからなかったので、データベースの中身をブレイクダンスに限定して再挑戦してみます。今度はAdvanced Danceに含まれる動画のうち、ジャンルがブレイクダンスの動画に限定して新たにQdrantにコレクションを作成します。
注意点としてAdvanced Danceに含まれる動画はサイズが大きいので、そのままVertex AIでベクトル化しようとするとProvided video excceeds allowed maximum video string length 27000000というエラーが発生します。事前にffmpeg等で動画のサイズを小さくしてからベクトル化しましょう。今回は以下のコマンドでAdvanced Dance内の全ての動画を変換してからVertex AIに渡しています。
ffmpeg -i <元データのファイル名> -c:v libx264 -s 1280x720 -crf 23 -an <変換後のファイル名>
世界一横であろう1990に類似する動画の検索(再)
Advanced Danceをもとに新しく作成したコレクションに対して改めて検索を実施してみます。ちなみにAdvanced Danceを利用することで検索対象をブレイクダンスに限定しつつ、動画の種類も増やすことはできましたが、相変わらず1990の動画は含まれていない状態です。
結果は以下のようになりました。
[{'id': 31,
'order_value': None,
'payload': {'end_offset_sec': 48.0,
'file_name': 'gBR_sFM_c01_d04_mBR2_ch03.mp4',
'genre': 'Break',
'seq': 2,
'situation': 'Advanced Dance',
'start_offset_sec': 32.0},
'score': 0.72965086,
'shard_key': None,
'vector': None,
'version': 30},
{'id': 30,
'order_value': None,
'payload': {'end_offset_sec': 32.0,
'file_name': 'gBR_sFM_c01_d04_mBR2_ch03.mp4',
'genre': 'Break',
'seq': 1,
'situation': 'Advanced Dance',
'start_offset_sec': 16.0},
'score': 0.7276319,
'shard_key': None,
'vector': None,
'version': 29},
{'id': 11,
'order_value': None,
'payload': {'end_offset_sec': 29.0,
'file_name': 'gBR_sFM_c01_d06_mBR5_ch19.mp4',
'genre': 'Break',
'seq': 1,
'situation': 'Advanced Dance',
'start_offset_sec': 16.0},
'score': 0.72740114,
'shard_key': None,
'vector': None,
'version': 10}]
「世界一横であろう1990」に最も類似しているのはgBR_sFM_c01_d04_mBR2_ch03.mp4の32~48秒のようです。
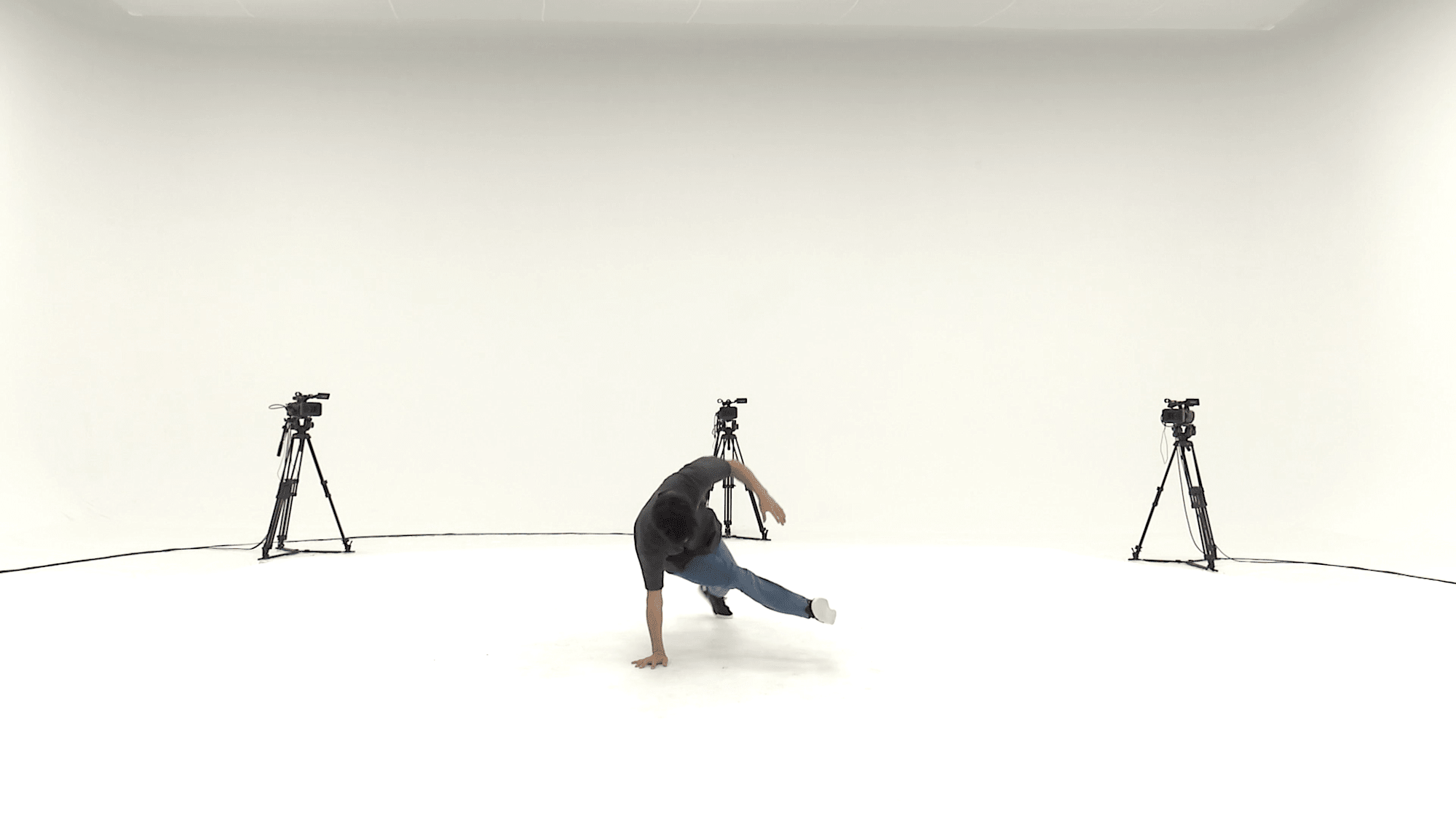
トーマスの動画に類似する動画の検索
やはり検索対象のデータベースに存在しない技を検索するのは無理がありそうなので、今度はトーマスの動画を検索してみます。トーマスはAdvanced Danceに含まれる動画gBR_sFM_c01_d06_mBR4_ch20.mp4の18 ~ 21秒あたりに含まれているため、この動画がヒットするのが理想的です。
検索に使った動画の切り抜きはこんな感じです。

検索結果は以下の通りになりました。
[{'id': 50,
'order_value': None,
'payload': {'end_offset_sec': 32.0,
'file_name': 'gBR_sFM_c01_d04_mBR4_ch07.mp4',
'genre': 'Break',
'seq': 1,
'situation': 'Advanced Dance',
'start_offset_sec': 16.0},
'score': 0.74238,
'shard_key': None,
'vector': None,
'version': 49},
{'id': 51,
'order_value': None,
'payload': {'end_offset_sec': 48.0,
'file_name': 'gBR_sFM_c01_d04_mBR4_ch07.mp4',
'genre': 'Break',
'seq': 2,
'situation': 'Advanced Dance',
'start_offset_sec': 32.0},
'score': 0.7405085,
'shard_key': None,
'vector': None,
'version': 50},
{'id': 11,
'order_value': None,
'payload': {'end_offset_sec': 29.0,
'file_name': 'gBR_sFM_c01_d06_mBR5_ch19.mp4',
'genre': 'Break',
'seq': 1,
'situation': 'Advanced Dance',
'start_offset_sec': 16.0},
'score': 0.73342156,
'shard_key': None,
'vector': None,
'version': 10}]
検索にヒットしたgBR_sFM_c01_d04_mBR4_ch07.mp4の16 ~ 32秒を確認したところ、片手で逆立ちしてピョンピョン跳ねる「ステッピン」の動画でした。
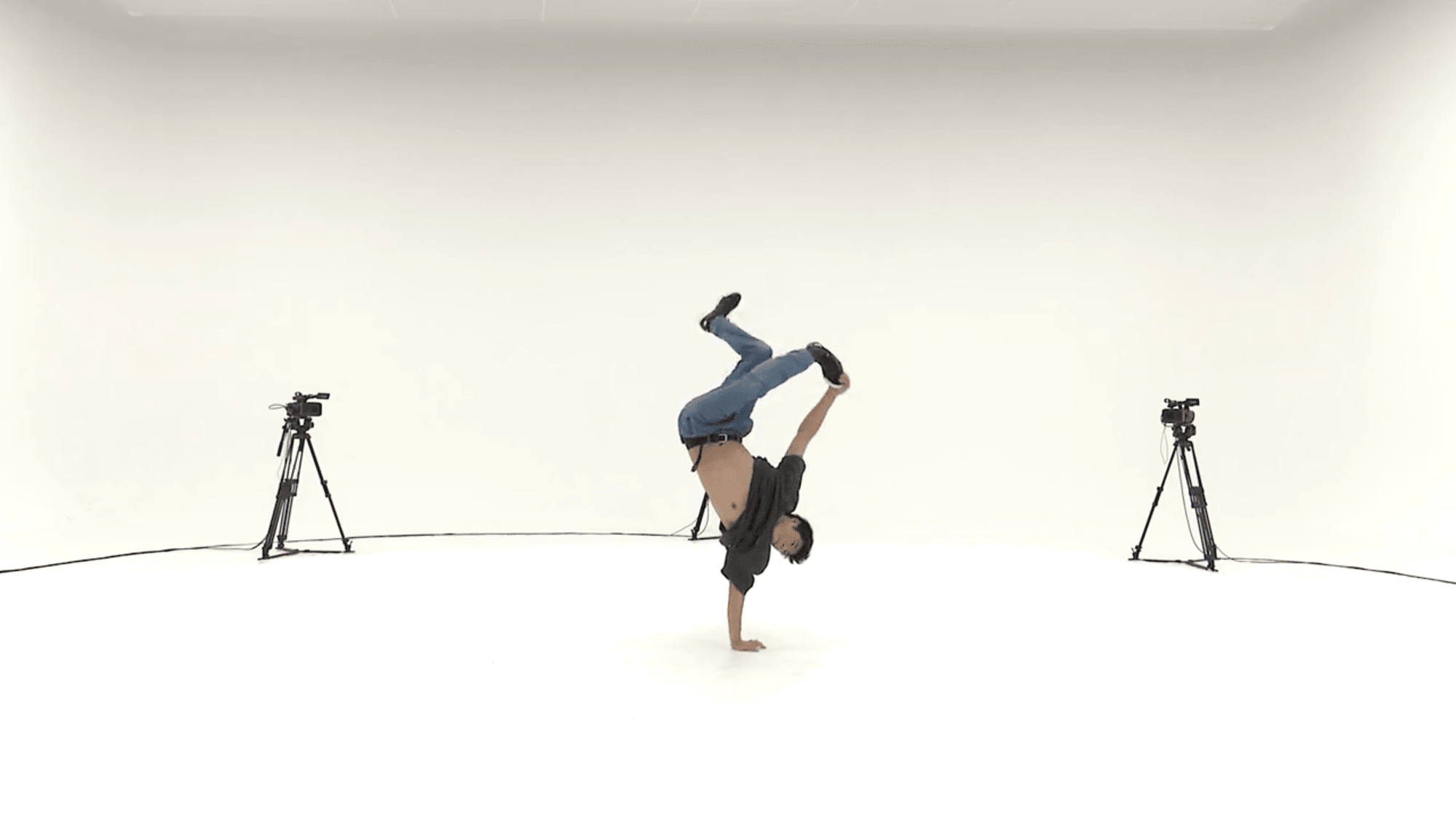
素人目にも分かりやすくスゴいという点では共通度が高いですが、残念ながら同じ技を含む動画gBR_sFM_c01_d06_mBR4_ch20.mp4はヒットしませんでした。今回は動画検索のイメージを掴むことを目的として諸々のパラメータはデフォルト値で試していますが、パラメータ調整によってどのように結果が改善されるか深堀りしてみるのも面白そうです。
まとめ
ダンス動画を題材にVertex AIによるベクトル化とQdrantによる検索を試してみました。
Vertex AIでベクトル化する際にはinterval_secというパラメータを指定することでエンベディングを生成する間隔が調整でき、デフォルトでは16秒毎に1つのエンベディングが生成されます。様々な動きが含まれる動画であればこの間隔を短くすることで、各エンベディングがより動画の特徴を捉えたものになることが期待されます。
また、今回Qdrantのコレクションを作成する際に類似度の計測方法としてコサイン類似度を指定しましたが、Qdrant自体は以下の4つに対応しています。
- コサイン類似度
- ドット積類似度
- ユークリッド距離
- マンハッタン距離
この辺りのパラメータを調整すると違った結果が出て面白そうなので、また色々なパターンを試してみたいです。
参考
- マルチモーダル エンベディングを取得する | Vertex AI の生成 AI | Google Cloud
- Local Quickstart - Qdrant
- Search - Qdrant
- AIST Dance Video Database (AIST Dance DB)
- AIST Dance Video Database: Multi-genre, Multi-dancer, and Multi-camera Database for Dance Information Processing
- AIST Dance Video Database: ダンス情報処理研究の ためのストリートダンス動画データベース
- AIST Dance Video Database: ダンス情報処理研究のためのストリートダンス動画データベース | PPT
おまけ
リルオッサ氏の「世界一横であろう1990」と筆者の「2000」の類似度は 19.990952 でした。
90度回転させたら大体同じだと思うんですけどね🤔






